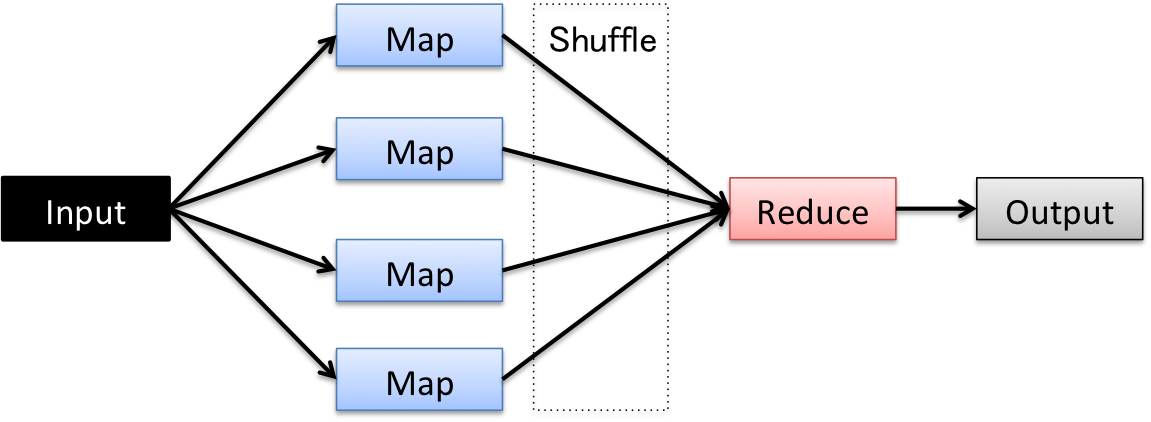
In this subcourse, we develop a Hadoop PaaS for data analytics. The Apache Hadoop is an open source implementation of MapReduce distributed computing platform. MapReduce programming paradigm divides a distributed computing program into two parts; map and reduce, as shown in Figure 1. The map operation distributes programming blocks into multiple processors, and the reduce operation gathers the results of the map operation to yield the result of the program. Data passing to the map and reduce operations as well as input and output data are shared through a distributed filesystem called HDFS.
A Hadoop cluster is a master-slave system. Therefore, we prepare two instance templates; one is for master, and the other is for slave. The system we develop in this subcourse will provision clusters to users (not automated at its initial design). It also implements the features of PaaS such as elastic scaling in Hadoop clusters. Note that the initial design of the system assumes “manual operation“ but can be automated by designing and implementing user interfaces.
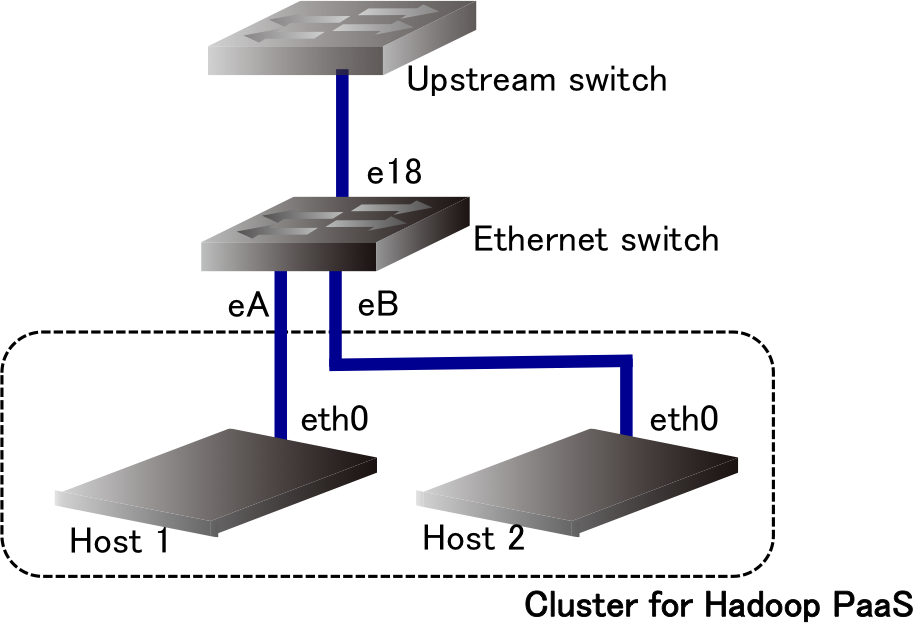
We will use two physical hosts for this subcourse. The network interface of each host connects to an ethernet switch (an untagged port of the global IPv4/IPv6 network segment). Figure 2 illustrates the physical topology for your Hadoop PaaS. Each Hadoop node will be launched on these hosts using Linux Containers (LXC).
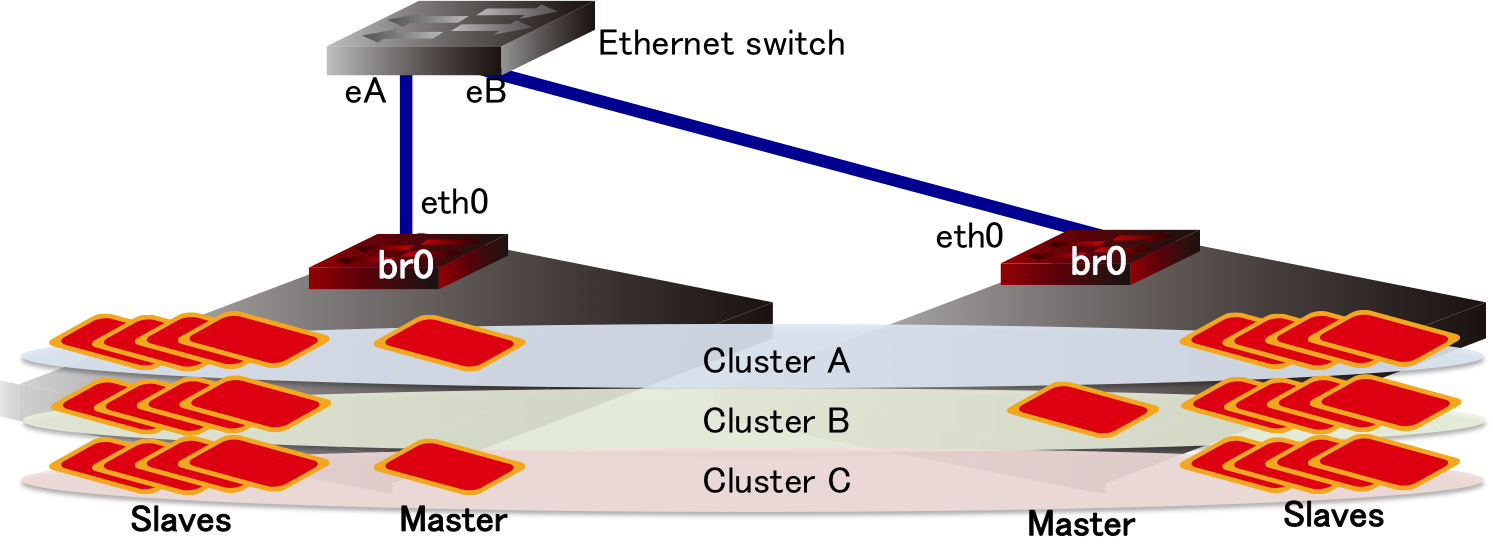
On the physical topology, we launch Hadoop clusters. Each cluster is created from the LXC instance templates of master and slave nodes that will be explained and prepared later. Figure 3 presents the system overview. Each cluster runs one master node and multiple slave nodes. All the nodes are connected to the same (global) segment. Note that it is better to use private network for internal network among Hadoop nodes andto use different VLANs for each Hadoop cluster to separate virtual network used by a cluster of hadoop nodes among different users. However, we do not do it for simplicity of the system at the initial design.
The Linux Containers (LXC) is a virtualization environment to run multiple Linux operating systems on a single Linux operating system. An instance on the LXC are also called a light-weight virtual machine. We use the LXC to sepearate hadoop nodes of multiple users from each other. The LXC should be introduced in a previous class.
As mentioned above, a Hadoop cluster is a master-slave system. we prepare a template for master and slave hosts in the following sections. We use the same template of an LXC instance for master and slave nodes because there are few differences between master and slave nodes.
In order to create an LXC instance for the template, you can use the lxc-create command.
$sudo lxc-create -n template -t ubuntuLet me note that you need to change the default password and network configuration before going to the next step.
Since Hadoop is Java-based software, we first need to install Java Development Kit (JDK) onto your operating system. Fortunately, the package management system on Ubuntu server that we use provides a JDK package, named default-jdk. This JDK is installed by the following command:
$sudo apt-get install default-jdkWe add the hadoop user who runs Hadoop programs as follows.
$sudo useradd -m hadoopSince the start-up script of Hadoop cluster accesses slave nodes via SSH, we generate an SSH key pair for the hadoop user. This key pair is expected to be used only in this system and access control will be written in the authorized_keys file, so use empty password for the private key.
$sudo -u hadoop ssh-keygenYou need to add the contents of the public key ~/.ssh/id_rsa.pub into ~/.ssh/authorized_keys.
Note that the private key will be shared by different clusters. So you need to take care about that; for example, we must not provide console or filesystem access to Hadoop master instances to users. Another possible solution against this shared private key problem is to generate the key pair when a cluster is created although it may be a little complex.
We then create a directory for the distributed filesystem HDFS and change the owner to the hadoop user. at /var/hadoop.
$
$sudo mkdir /var/hadoop
sudo chown hadoop /var/hadoopNext, we install the hadoop package into your instance. The hadoop package can be downloaded from a mirror site:
$wget http://ftp.jaist.ac.jp/pub/apache/hadoop/common/hadoop-2.6.0/hadoop-2.6.0.tar.gzThe installation is done by simply extracting the directory like:
$sudo tar -C /home/hadoop -zxvf hadoop-2.6.0.tar.gzWe then configure the hadoop system. First, we set up the environment variables; insert the following lines to /home/hadoop/.profile at Line 6.
JAVA_HOME=/usr/lib/jvm/default-java
HADOOP_INSTALL=/home/hadoop/hadoop-2.6.0
PATH=$PATH:$HADOOP_INSTALL/bin
PATH=$PATH:$HADOOP_INSTALL/sbin
HADOOP_MAPRED_HOME=$HADOOP_INSTALL
HADOOP_COMMON_HOME=$HADOOP_INSTALL
HADOOP_HDFS_HOME=$HADOOP_INSTALL
HADOOP_CONF_DIR=$HADOOP_INSTALL/etc/hadoop
YARN_HOME=$HADOOP_INSTALL
HADOOP_SSH_OPTS="-o StrictHostKeyChecking=no"
export JAVA_HOME
export PATH
export HADOOP_MAPRED_HOME
export HADOOP_COMMON_HOME
export HADOOP_HDFS_HOME
export HADOOP_CONF_DIR
export YARN_HOME
export HADOOP_SSH_OPTSThe list of slave nodes (including the master node) should be listed in $HADOOP_CONF_DIR/slaves, but we will configure this later when a cluster is created from the template.
The HDFS is configured at $HADOOP_CONF_DIR/core-site.xml and $HADOOP_CONF_DIR/hdfs-site.xml. We will use a static name “master” for the master node and write the name resolution configuration to /etc/hosts. Edit the $HADOOP_CONF_DIR/core-site.xml file as follows:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
</property>
</configuration>
and edit the $HADOOP_CONF_DIR/hdfs-site.xml file to specify the number of replicas and directories used by HDFS indexes and data as follows:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/var/hadoop/hdfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/var/hadoop/hdfs/datanode</value>
</property>
</configuration>Hadoop adopts YARN to manage its MapReduce platform; which comprises ResourceManager (RM) and ApplicationMaster (AM). We then configure YARN at $HADOOP_CONF_DIR/yarn-site.xml as follows.
<?xml version="1.0"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
</configuration>To specify to use YARN, we configure the file $HADOOP_CONF_DIR/mapred-site.xml as follows.
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
</configuration>To secure your host against these attacks, disable password authentication. To disable password authentication, edit the /etc/ssh/sshd_config file as follows.
PasswordAuthentication noHere the preparation of the template for Hadoop nodes is completed. So, shutdown the template (LXC instance).
To understand how your PaaS will work and what you will develop, we provision a set of master and slaves from the template. In this example, we create one master and two slaves.
$
$
$sudo lxc-clone -o template -n cluster01-master
sudo lxc-clone -o template -n cluster01-slave01
sudo lxc-clone -o template -n cluster01-slave02
Edit /var/lib/lxc/cluster01-<master|slave01|slave02>/rootfs/etc/network/interfaces to configure the IP address of each instance from your IP address pool. You also need to edit /var/lib/lxc/cluster01-<master|slave01|slave02>/rootfs/home/hadoop/hadoop-2.6.0/etc/hadoop/slaves to list the IP addresses of these instances (including the master node).
Launch all the node and start the hadoop.
$
$
$sudo lxc-start -n cluster01-master -d
sudo lxc-start -n cluster01-slave01 -d
sudo lxc-start -n cluster01-slave02 -d
Now user can login to the master node, and launch hadoop program like:
$
$
$
$hdfs namenode -format
start-dfs.sh
start-yarn.sh
hadoop jar /home/hadoop/hadoop-2.6.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0.jar pi 100 100
Note that it is not good to provide shell user interface to users in the current design because the autholized keys are shared as mentioned before. Upon your design decision, you can disable and provide another interface to do the same thing, or any other solutions.
On a running hadoop cluster, the status of HDFS and YARN (MapReduce) is checked through http://<master-node-IP-address>:50070/ and http://<master-node-IP-address>:8088/, respectively.
In the previous section, you manually provisioned a hadoop cluster by yourself. The next step is making it automated. Please discuss the direction and the design of your Hadoop PaaS with your group members, and proceed your project! Developing a good user interface to provision and launch user program is also welcome.