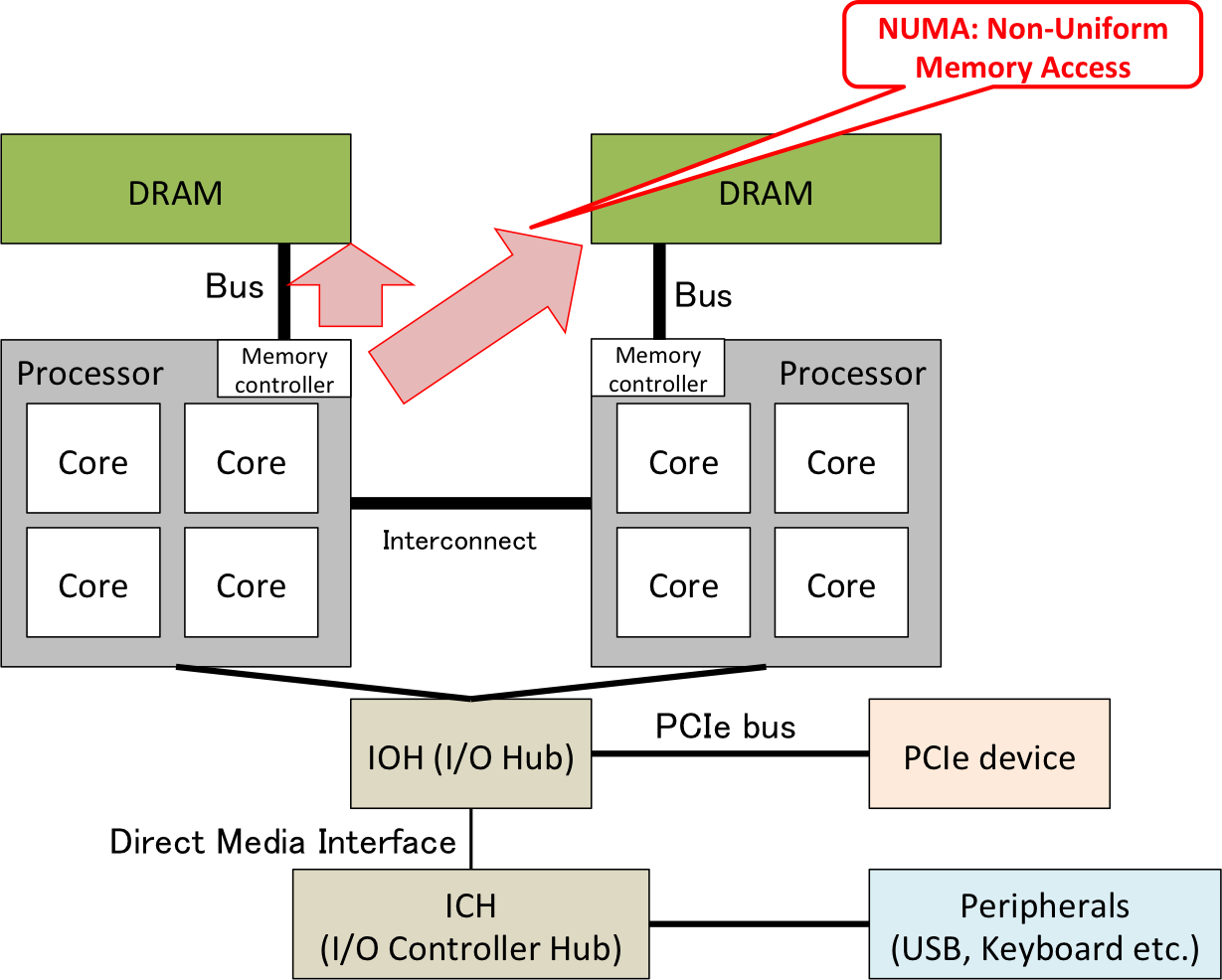
A general purpose computer is composed of central processing unit (CPU), main memory, buses, and peripherals such as display, secondary storage (e.g., hard disk drive (HDD), solid state drive (SSD)) and network interface card (NIC) through generic interfaces as shown in Figure 1. There exist various generic CPU architectures such as x86/x86-64 (Intel(R) 64, AMD 64) used in server or laptop computers, and ARM used in low power consumption devices like smartphones. In cloud computing, the x86-64 CPUs have been widely used because they support hardware virtualization assistance from their early models.
The CPU architectures are categorized into two groups from the viewpoint of the instruction set architecture (ISA) of the microprocessor; Complex Instruction Set Computing (CISC) such as x86/x86-64 CPUs, and Reduced Instruction Set Computing (RISC) such as SPARC, MIPS, POWER/PowerPC, and ARM. The CISC processors provide high-level single instructions that execute a set of primitive instructions. Therefore, the number of instructions and the size of single instructions tend to become large. On contrary, the RISC processors only provide primitive instructions so that the design of the microprocessors be simple. Usually, the size of single instructions of RISC processors is small and fixed.

To understand how a CPU works, we overlook the simplified CPU architecture. The execution of a single instruction is divided into five stages to implement pipelining; 1) Instruction Fetch (IF), 2) Instruction Decode (ID), 3) Execute (EX), 4) Memory Access (MA), and 5) Write-Back (WB). In the IF stage, an instruction is fetched from instruction (usually cache) memory. Then, it is decoded and registeres required by the instruction are selected for execution in the ID stage. The EX stage executes the decoded instruction. If the instruction is memory access (load or store), the MA stage loads/stores data from/to memory (or data cache) to/from CPU. The WB stage writes back the results of the EX/MA stage into registers. Note that the separation of the stages, i.e., the number of stages, varies by CPU design. Figure 2 illustrates the five stage pipelining. Since separation of stages incurs some overheads to align each stage by cycle (clock), the time consumed by a single instruction without staging is considered shorter than that with staging. However, since multiple instructions simultaneously run on a single processor, pipelining drastically improves throughput.
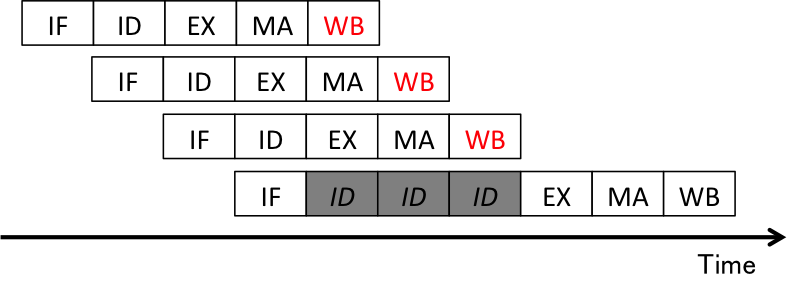
Although pipelining improves throughput, it leads to problems with parallel execution of each stage, called hazards. There are three types of hazards; structural hazards, data hazards, and control hazards. Structural hazards are led by hardware resource conflicts among different stages. For example, the ID and WB stages both access registers, so these two stages cannot be run at the same cycle as shown in Figure 3. Data hazards are led by data dependencies. For example, as shown in Figure 4, the result of the first instruction, r3, is used by the second instruction, so the ID stage of the second instruction needs to wait until the WB stage of the first instruction is completed. Control hazards are similar to data hazards, but the difference is that control hazards are led by uncertainty of branch instructions. For example, as shown in Figure 5, the result of a branch instruction, e.g., the next instruction pointer, is used by the following instruction, so the IF stage of the instruction waits until the WB stage of the branch instruction is completed.


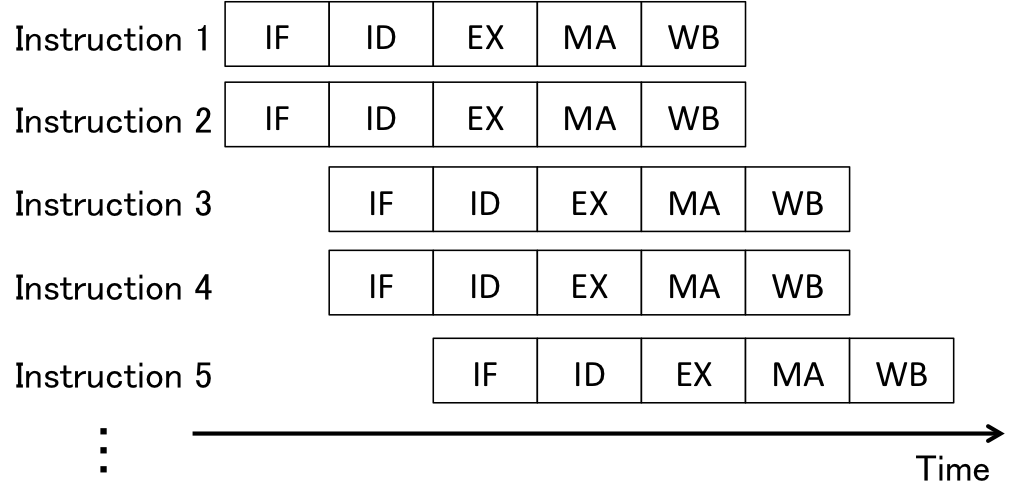
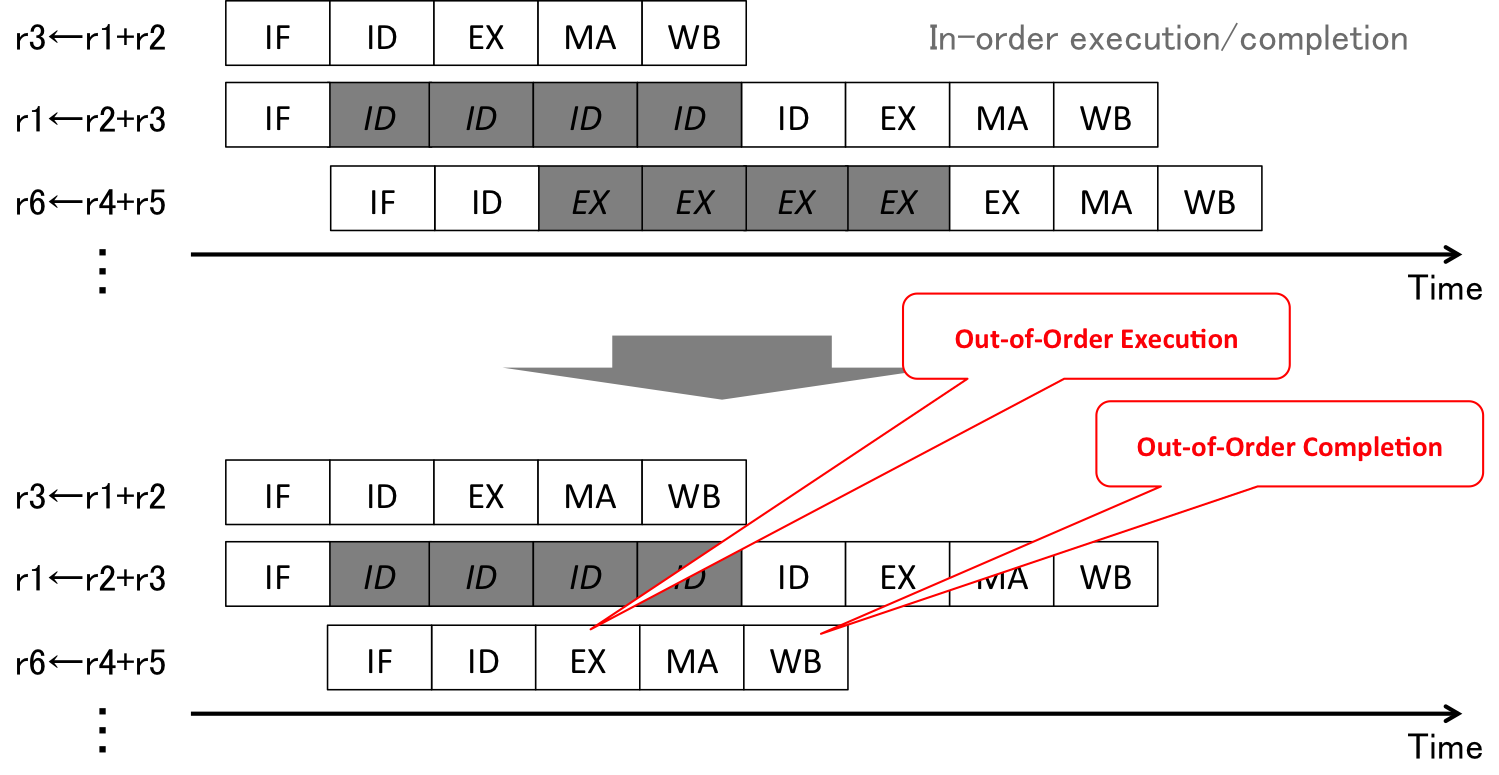
CPUs can be categorized into two types from the viewpoint of the operation of instructions; scalar and vector processors. Scalar processors are designed to operate scalar values in single instructions, while vector processors are designed to operate arrays of values, i.e., vectors, in single instructions. Vector processors are used for high-performance computing or in graphic processing unit (GPU). The generic CPUs are basically scalar processors, but recent models of CPUs implement multiple scalar processing components, called superscalar, in one CPU (core). Figure 6 illustrates how a superscalar processor works. A superscalar processor operates multiple instructions at the same time. The concept of superscalar scalar processors leads to many data hazards. Therefore, superscalar processors usually implement the out-of-order execution/completion mechanism. Figure 7 shows an example of the out-of-order execution/completion. One of the input registers, r3, in the second instruction depends on the result of the first instruction, but the third instruction has no dependencies. Therefore, the third instruction can be executed and completed before the second instruction is executed and completed.
An Operating System (OS) takes in charge of the abstraction of underlying hardware and the resource management. For the abstraction of underlying hardware, OSes provide the abstracted interfaces/mechanisms to different underlying hardware; for example, both floppy disk drives and hard disk drives are recognized as block devices through an OS. For the resource management, OSes manage the resources such as CPU and memory and let them share among different tasks as illustrated in Figure 8. The resource management mechanism for CPUs among tasks is called scheduler.

OSes have been developed for various systems. As the request from users to the operating system, many scheduling algorithms have been developed. Here, I list the well-known algorithms as follows.
Other fundamentals are explained with slides.